


Generative language models like ChatGPT can answer almost any question quickly and are easy to use. But if you look closely, you will also notice some problems.
Advertisement


Is a data scientist and machine learning architect. He has a PhD in Theoretical Physics and has been working in the field of big data and artificial intelligence for over 20 years, particularly focusing on scalable systems and intelligent algorithms for large-scale text processing. As a professor at the Technical University of Nuremberg, his research focuses on optimizing user experience using modern methods. He is the founder of Datanizing GmbH, speaker at conferences, and author of articles on machine learning and text analytics.
First, there are hallucinations: what language models say is not always correct. If the model doesn’t know some information, it adds some information. The hallucinations are so convincingly crafted that they seem believable. The first version of Llama immediately made Heise-Verlag the organizer of CeBIT. Perhaps the combination of publication, IT context and location in Hanover was too obvious for the model, which was the world’s largest computer trade fair at the time. The sophisticated formulation leads anyone to believe such misinformation.
Training large language models is also extremely complex and can take several thousand GPU years of computing time. Therefore, providers rarely retrain models. This means that the models do not know the current information. Even for relatively new models like Llama 3.1 there is a so-called knowledge cutoff last year,
Public language models fail when it comes to statements about internal information, for example of a company, because this material is not included in their training set. Generative models can be retrained (fine tuned), but this also requires a lot of effort (and has to be done again for each document added).


Well combined: LLM + RAG
Combining generative models with modern information retrieval methods can help. Documents can be indexed using embedding models (these also belong to the class of large language models). Using similarity metrics, you can find documents (or paragraphs) that answer a question as best as possible. This “context” is then sent to a generative model that summarizes the results and matches them exactly to the question.
Such methods, called Retrieval Augmented Generation (RAG), are extremely popular. Last year, this started a small revolution in information retrieval because it can yield much better results. This is one reason why there are many frameworks that implement RAG.
Using RAG correctly is not trivial, as optimization is possible in different dimensions. You can work with different embedding models, use different enhancers, and use different generative models. Choosing the right combination requires considerable experience.
Furthermore, extracting (formal) knowledge from documents with pure RAG is unfortunately not yet possible. But it would be useful because models can give much better answers. Research on knowledge graphs has been going on for a long time. So it would be good if you could tie these two ideas together.
Hierarchical access with GraphRAG
The term GraphRAG comes from Microsoft, and introductory article The process has been described as a hierarchical approach to RAG as opposed to a purely semantic search for text fragments. The individual steps include extracting knowledge graphs from raw text and creating community hierarchies with content summaries. These structures can then be used for retrieval and thus produce better answers.
However, unlike many other Microsoft projects, the implementation remains hidden. it jupyter notebooksBut they use Azure and OpenAI intensively and transfer all information to the cloud. Since so many things are hidden in classrooms, it is difficult to understand what is happening behind the scenes.
Fortunately, alternative sources and implementations exist. is recommended Introductory article by NumalHere you can see more clearly what is happening. An embedding model (intfloat/e5-base) makes it possible to create similarity queries. Existing Wikipedia embeddings, made available through Numeral Hugging Face, serve as the database. The implementation indexes a subset (the top 100,000 articles) and delivers a graph as the result of a query (here “machine learning”):


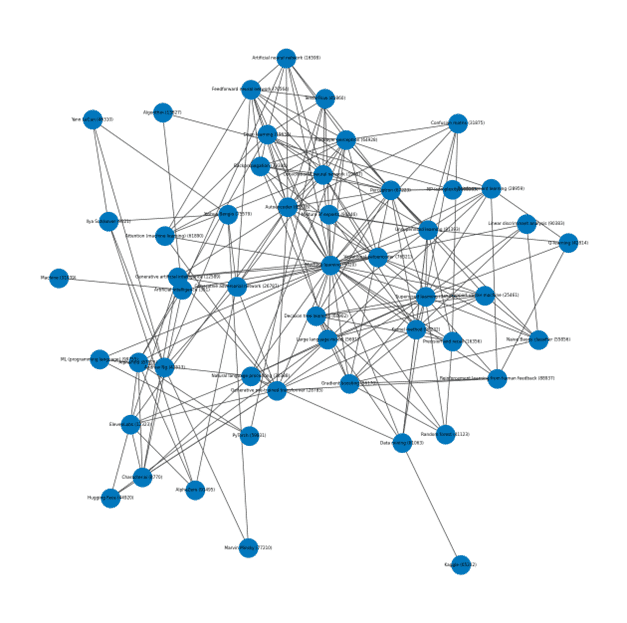
The Numal tool creates a knowledge graph for “Machine Learning” from the Wikipedia summary (Figure 1).
(Image: Christian Winkler)
The fact that the nodes in the upper part of Figure 1 are much more closely connected to each other than in the rest of the graph is an indication that information density is likely to be highest there.
Since the graph is modeled as a NetworkX graph in Python, its methods can also be called to determine the path between two nodes or to determine the nodes with the highest betweenness centrality, among other things. A look at the results shows that these are particularly relevant Wikipedia pages:
{'id': 'Machine learning',
'text': 'Machine learning (ML) is a field of study in artificial intelligence concerned with the development ...',
'topic': 'artificial_learning_intelligence_language',
'topicrank': 2,
'score': 0.9113607406616211}
{'id': 'Supervised learning',
'text': 'Supervised learning (SL) is a paradigm in machine learning where input objects (for example, a vecto...',
'topic': 'artificial_learning_intelligence_language',
'topicrank': 68,
'score': 0.8619827032089233}
{'id': 'Perceptron',
'text': 'In machine learning, the perceptron (or McCulloch–Pitts neuron) is an algorithm for supervised learn...',
'topic': 'artificial_learning_intelligence_language',
'topicrank': 70, 'score': 0.8862747550010681}
{'id': 'Autoencoder',
'text': 'An autoencoder is a type of artificial neural network used to learn efficient codings of unlabeled d...',
'topic': 'artificial_learning_intelligence_language',
'topicrank': 46,
'score': 0.8562962412834167}
{'id': 'Multilayer perceptron',
'text': 'A multilayer perceptron (MLP) is a misnomer for a modern feedforward artificial neural network, cons...',
'topic': 'artificial_learning_intelligence_language',
'topicrank': 89,
'score': 0.8532359004020691}
{'id': 'Unsupervised learning',
'text': 'Unsupervised learning is a paradigm in machine learning where, in contrast to supervised learning an...',
'topic': 'artificial_learning_intelligence_language',
'topicrank': 53,
'score': 0.8743622303009033}
{'id': 'Generative pre-trained transformer',
'text': 'Generative pre-trained transformers (GPT) are a type of large language model (LLM) and a prominent f...',
'topic': 'artificial_learning_intelligence_language',
'topicrank': 5,
'score': 0.8358747363090515}
{'id': 'Convolutional neural network',
'text': 'Convolutional neural network (CNN) is a regularized type of feed-forward neural network that learns ...',
'score': 0.8500866889953613}
{'id': 'Deep learning', 'text':
'Deep learning is the subset of machine learning methods based on artificial neural networks with rep...',
'topic': 'artificial_learning_intelligence_language',
'topicrank': 27,
'score': 0.8632184267044067}
{'id': 'Kernel method',
'text': 'In machine learning, kernel machines are a class of algorithms for pattern analysis, whose best know...',
'topic': 'artificial_learning_intelligence_language',
'topicrank': 99,
'score': 0.8539000749588013}
The score comes from similarity analysis, and you can clearly see that the order is different from graph analysis. By combining both methods, you can find the most relevant documents for both the query and the context.
The topics that appear in the results are also interesting. These were calculated during indexing – the process is quite complex and, like the calculation of embeddings, is several orders of magnitude faster on a GPU than a CPU.
The final stage of RAG, text generation, also requires powerful hardware. Numeral’s example uses the Mistral 7b OpenOrca model. To ensure that it runs even on GPUs that are not as powerful, Numeral opted for a model that is downsampled using Activation-Aware Weight Quantization (AWQ). Hence generation is quick and facts can be extracted from the graph. The Wikipedia tool answers the question “Machine Learning” as follows:
- Machine learning is a field of study in artificial intelligence that focuses on developing statistical algorithms that can learn from data and generalize to unseen data.
- Generative artificial neural networks have outperformed many previous approaches in performance.
- Machine learning algorithms are susceptible to inheriting and amplifying biases present in their training data, which may manifest in disproportionate representation or unfair treatment of different demographics.
- Supervised learning is a paradigm in machine learning where input objects and desired output values train a model, allowing the algorithm to correctly determine output values for unseen examples.
- Autoencoders are a type of artificial neural networks used for unsupervised learning, efficient coding of unlabeled data, and dimensionality reduction.
What is surprising is that the answer focuses on generative AI. The model reflects information that can be found on Wikipedia. There is clearly a lot more to learn about generative (language) models than other ML topics. It is also surprising that the model explains autoencoders in addition to supervised learning, but not unsupervised learning.
In addition to Jupyter Notebook excerpts, Numal also offers A Streamlit application on GitHub use. This tool is powerful and also allows you to index your documents.






{kind=link}